Datasets
A dataset is a collection of data that can be read and written to in a graph using Read and Write operations. Unlike static inputs and global constants, which are suitable for small data and user-defined scalars, datasets are designed for large data, such as training and evaluation sets, as well as layer weights. In Graphbook, a dataset refers to any data that is read and written in a graph.
Importing a Dataset
To import a dataset, click the Import button under the Datasets overflow menu or navigate to File > Use Dataset from Local. The dataset will be uploaded to your free cloud account and made available for use in Graphbook projects.
Dataset Formats
Graphbook currently supports the following dataset formats:
- JSON
- CSV
- IMAGE
Adding a Dataset
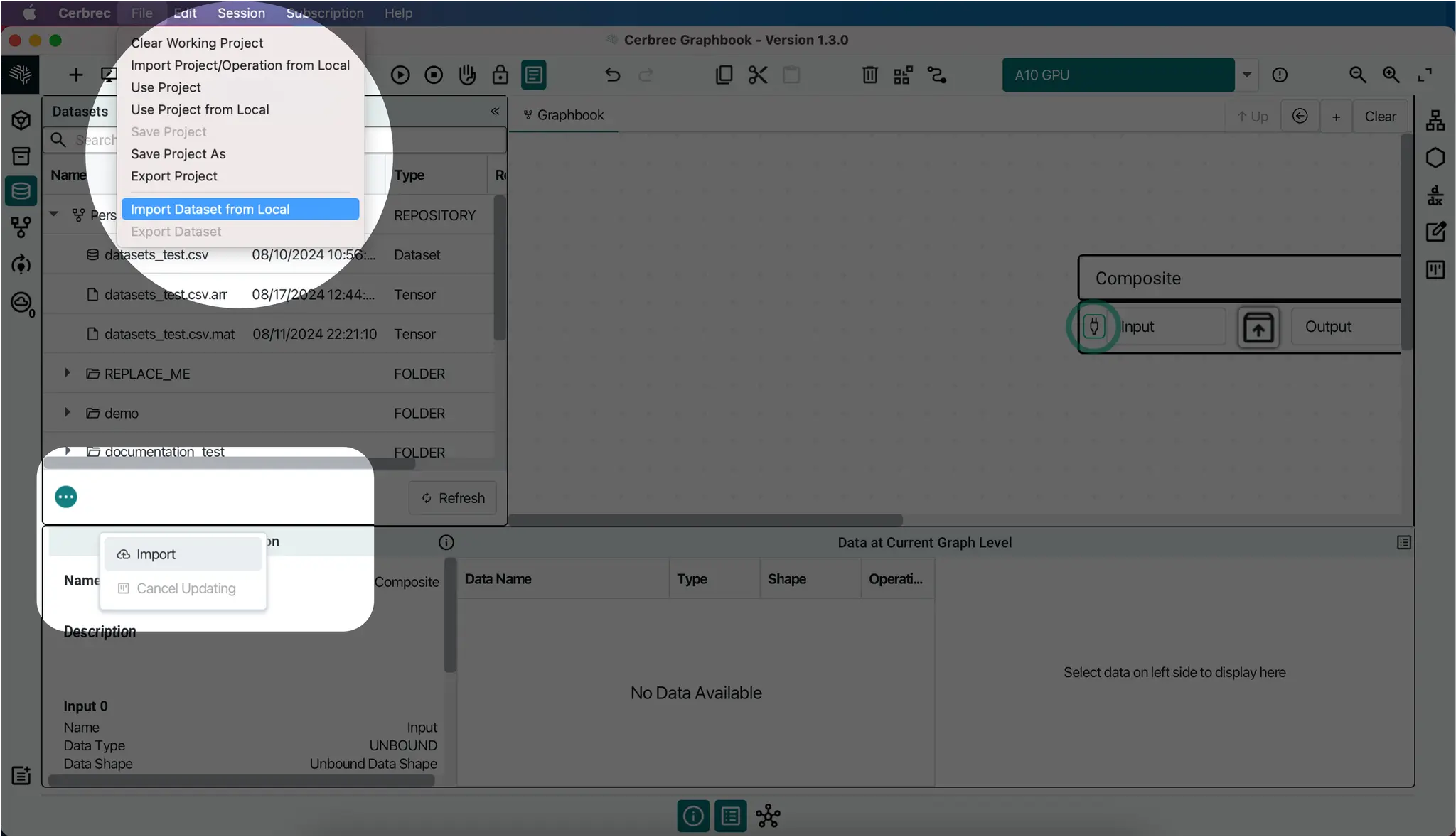
Once the data is imported, you can drag and drop a dataset into the Graph Canvas or select File > Use Dataset In Project. This will automatically open the Convert Dataset To Tensor window.
Convert Dataset To Tensor
This window provides several options for reading the dataset into a data (tensor) format:
- Dataset Preview: A preview of the file's contents is displayed on the left-hand side.
- Extraction Schema: A tree view of the extraction fields is shown in the middle.
- Extracted Data Snippet: A preview of the data in tensor format is displayed on the right-hand side.
To accept the data as is, click the Submit button. This assumes the data is already in tensor format and ready to read from the file.
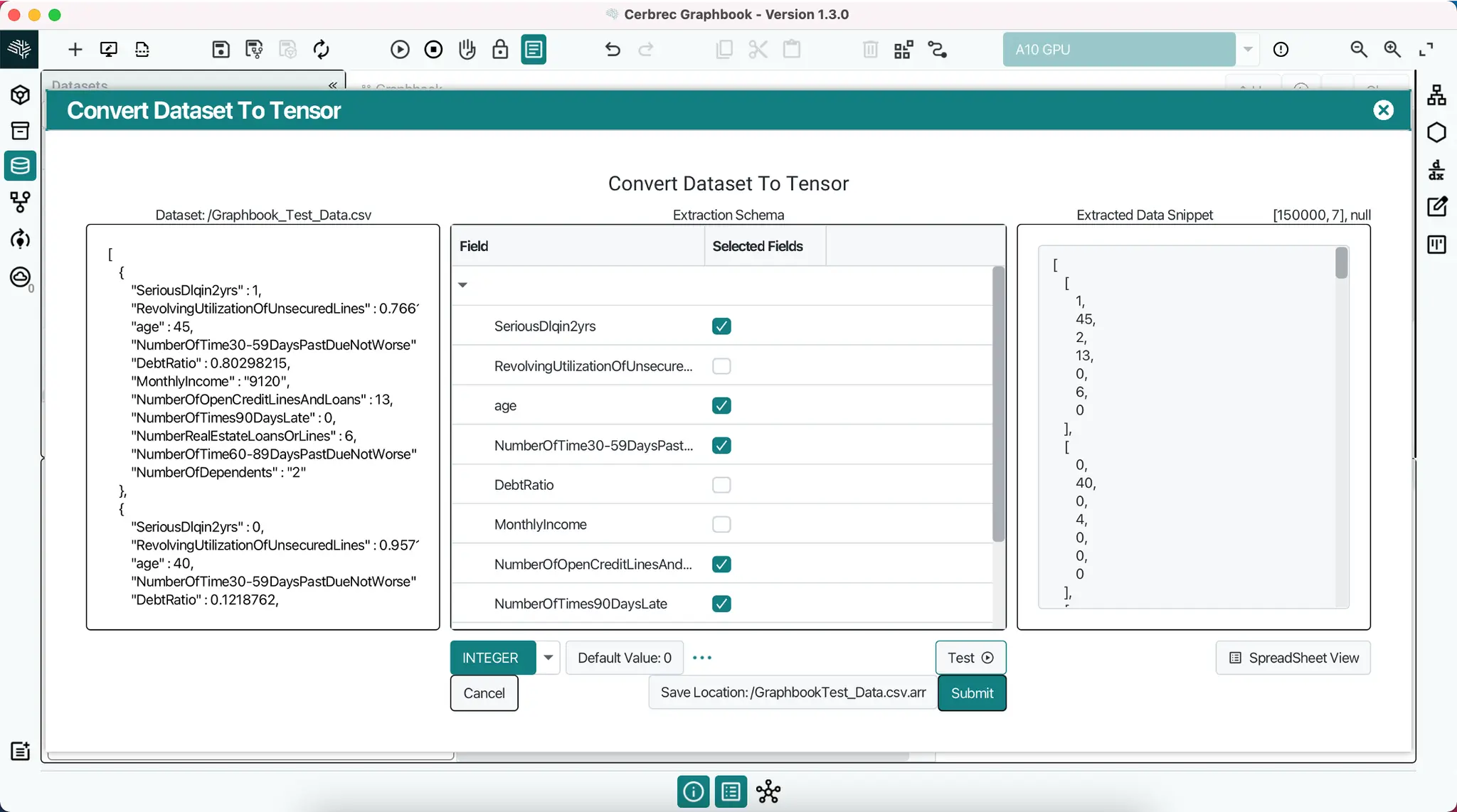
Auto-Populating on Canvas
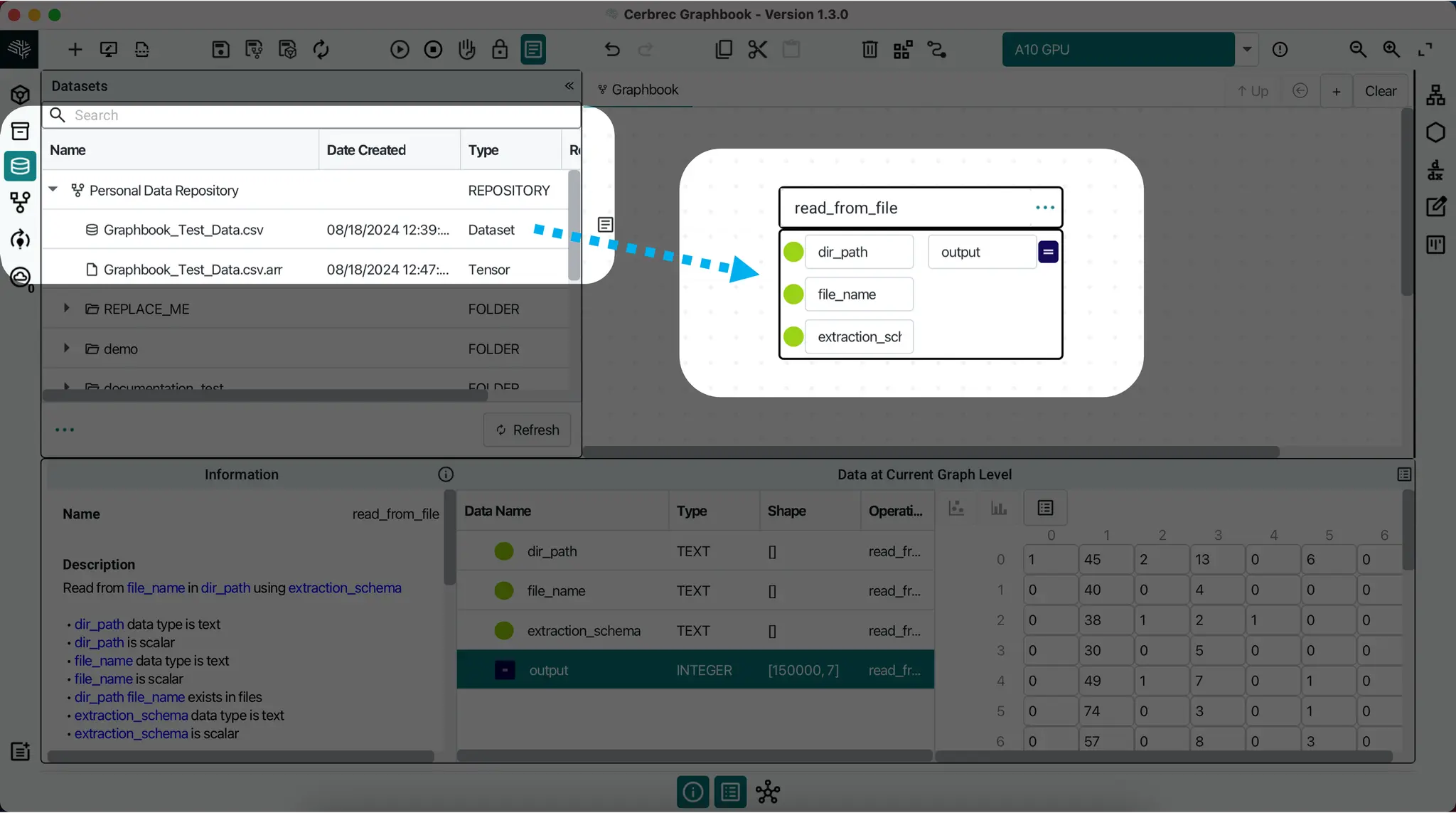
Once you've submitted your data, a read_from_file operation will be auto-populated in the Graph Canvas. It has 3 inputs and 1 output:
dir_path: Text scalar of directory pathfile_name: Text scalar of dataset file's nameExtraction Schema: Defines how data is extracted from a fileOutput: Data in tensor format
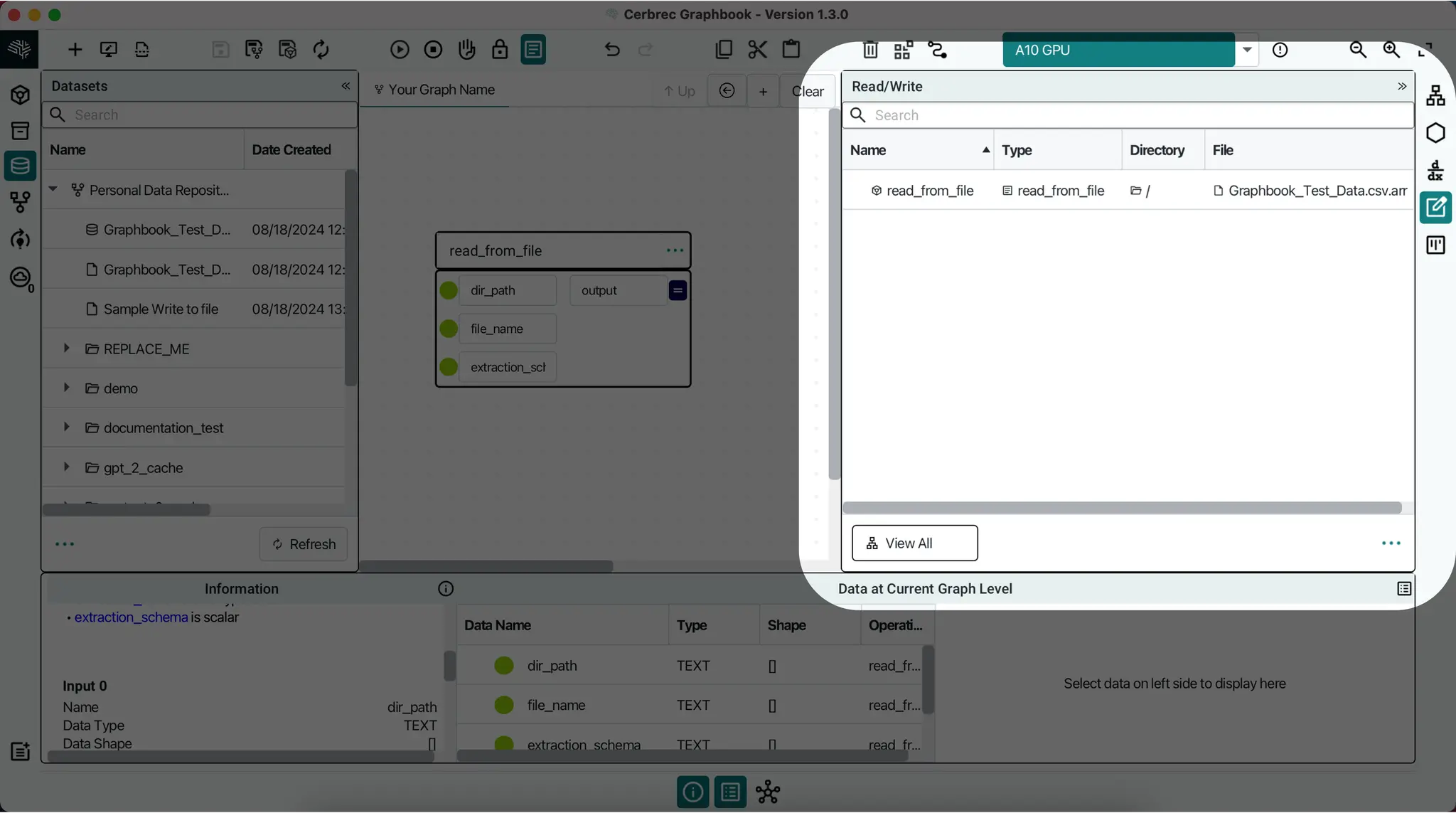
Read/Write Panel
When there are many datasets in your project, such as reading in many weights, you may want to see a global view of all places they are used. On the Right Panel, you can select the Read/Write Panel to see a list of all read and write operations at or below your current graph level.
Writing to a Dataset
To write data to a file in Graphbook, use the write_to_file operation. It has 4 inputs:
dir_path: Text scalar of directory pathfile_name: Text scalar of dataset file's nameis_overwrite: Boolean scalar indicating whether to overwrite the contents if the dataset already existsdata: Dataset to be written
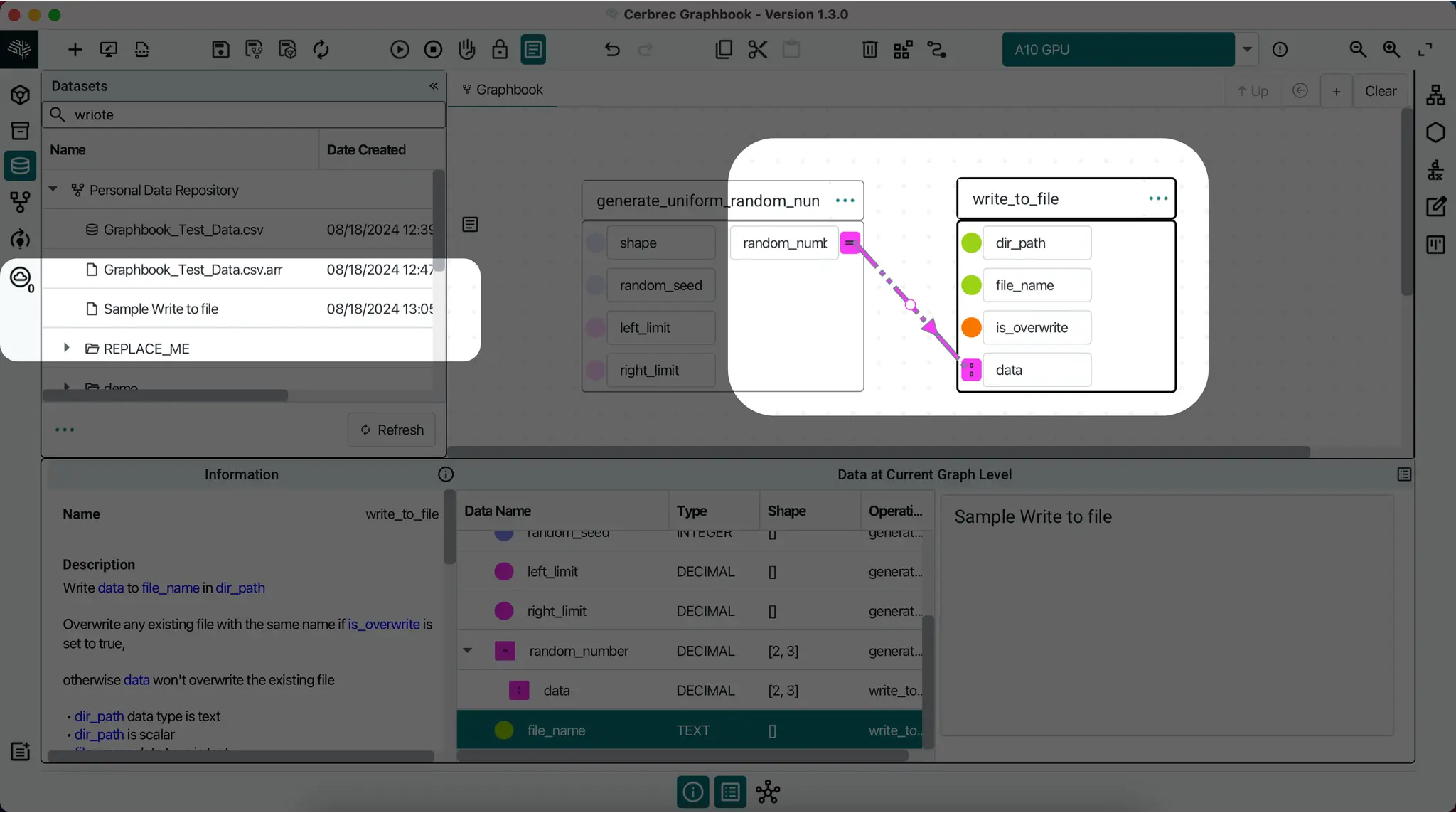
write_to_file operation has no outputs. It simply writes the data to the file in Compute Result format.Update Date Directory
To determine where data will be stored, refer to the Directory column under the Read/Write Panel. In this example, the data will be stored in the layer_x folder. The curly brackets $ indicate that this value will be substituted with a global constant value. The root directory of the example data is currently set to REPLACE_ME.
Updating the Directory Path:
To reassign the directory path, follow these steps:
- Click on the overflow menu of the operation and select
Edit Dir Paths, or right click on single directory for certain data row under the Read/Write Panel and selectEdit Dir Paths - In the Edit Dir Path window, update the directory path by replacing
layer_xwith the desired subdirectory, e.g.,layer_0. - Click Apply to save the changes.
After updating the directory path, the data will be saved in the new ${Training Directory}/layer_0/ location. The updated directory path will be reflected in the Read/Write Panel and Datasets Panel. Note that to edit the root directory, you will need to update the Training Directory global constant. However, within a single model, it's common to only edit the subdirectory.
Reading Sub-Arrays from a Dataset
Suppose your dataset is large and you want to iterate over sub-arrays in your dataset. For example, when training, you may want to read just a batch-size worth of data from your dataset.
For that purpose, you can use the read_sub_arrays_from_file operation. This operation has 4 inputs:
dir_path: Text scalar of directory pathfile_name: Text scalar of dataset file's nameselected_indices: 1-D array of integers ≥ 0 indicating which indices of the dataset array to readdimension_index: Integer scalar (default = 0) specifying which axis to consider for selected indices